We are going discuss about a lot of topics here. SO, lets take an overview.
- Main theme of object tracking
- Main components (Object Detection and Re-IDentification)
- Types and variations (Online vs. Offline, One Step vs Two Step, Anchor Based vs Anchor free)
- Famous Object tracking datasets
- State-of-the-art models
- Object tracking metrics
So, I hope you understand, This is going to be a long journey, I even may end up dividing it in two parts. So grab a coffe and lets jump in...
Main theme of object tracking
Object tracking has been a longstanding goal in computer vision. The goal is to estimate the trajectories of multiple objects of interest in videos. The successful resolution of the task can benefit many applications such as action recognition, sport videos analysis, elderly care, and human computer interaction.
Unlike image classification(which is considered to be one of the solved problem of CV, that's why the focus is moving to other fields , like 3D image classification), object tracking is considered to be an active research field of Computer vision.
Just like we learn to walk before running, Our first goal in object tracking was tracking a single object in a video (Single Object Tracking - SOT) .

As time passed, we moved to more complicated tasks, as a consequence, today we are mostly dealing with tracking multiple objects like cars, persons etc. (Multiple Object Tracking - MOT).
Hopefully you can understand, this is considerably a difficult task than the previous one mentioned, as all persons and all cars look almost similar from a distance footage.
Yet there are more problems. Often we see some objects are occluded from the footage, like a person getting into a car or getting out of a car. Besides, often the person or object moves so fast that its position changes considerably between two subsequent frames. So the model has to initiate or close a trajectory in the middle of a video footage. We are trying and also succeeding to overcome these and many other obstacled, and to make tracking computation and memory efficient.
Main components
In machine learning some problems are solvable in one shot, like image classification ( The total process can be completed only with one convolution network). Some are not, like Object detection(some network is used for extracting features from image, another for specifying the location of an object, some other for determining the best height and width for bounding the object with a box). One shot processes are faster, so researchers are finding methods to execute all the processes in single shot.
The main process of object tracking is divided into two tasks. Firstly detecting all objects in each frame of a video, and identifying a specific detection in each frame (actually only in those frames where that specific object is present) of that video.
Object Detection: This part is simply detecting various objects in an image (frame of video), and drawing bounding box around that. This task is often done in two or three steps.Object detection , by itself is such a huge and evolving field of computer vision.Some of the best models for this task are : YOLO(v1....v5), Faster R-CNN, SSD and a lot others. But for now , were dont need to dive deeply here.
Re-ID: Now you must be thinking, isn't detection enough? Isn't out target detecting all objects trough all frames? Sadly no. We are yet to assign a detection to a specific object(ID), to track its movement and finally finding the trajectory of that object (and similarly to every individual object in the video). That is the task of the process Re-IDentification, Identifying the same objects again and again in every frame.
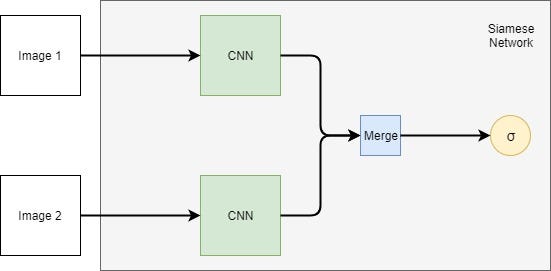
There has been a lot of work its improvement, yet we haven,t got the best of re-Identification. A vary populur approach for this is use of Seamese Network. Lets describe it briefly.HEre we usually train the model to learn similarity between two images. We will input two images to exactly same convolutional model, and the model is set to output the similarity score between those images. It will give a higher similarity score if those two input image represent the same object. Otherwise, low score. For efficient convergence, triplet loss or group loss are used as loss function.(Lets discus the loss functions some other day, but you can always google)Do you know, this is one of the most used algorithm for famous Face verification process, that we often encounter at ouur phone? and seamese network is cameble of learning with very small training dataset, that's why it is considers few shot learninig algorithm.
Types and variations
Like any other thing creation in this mortal world, object tracking algorithms also have a number of variations. Some variations are for making it fast, some changes make it computational cost efficient, and some are just to be there. We will dis cuss about two or three important ones.
Online vs. Offline: Some tracking models are completely trained on stored dataset whereas some can be trained on live streaming footage. Both method has some advantages and some shortcomings.
Models that are suitable for training on live streaming video, are usually vary fast. Actually they are bound to be fast, otherwise it is impossible to cope up with the video frame rate. of this speed, these models can be used for live object tracking. Some important online models are:
No comments:
Post a Comment